Multi Agent Flock RL with Shared Experience (Part 1)
The code for this project can be found on it’s github repo
Introduction
With this project I wanted to look at applying RL to a flocking model but also to see if the flock as a whole can be driven by a single RL agent interacting with itself, despite treating the members of the flock as individuals.
The boid model contains rules designed to emerge flocking behavior (as you might see in large bird flocks, or fish shoals) but it’d be interesting to see if these behaviours could be learnt from the bottom up, i.e. the RL agent not learning a policy for the flock as a whole, but a policy at the individual agent level. This might then be a nice route to generating behaviours for other agent based models.
Boids Model
The boid model was developed by Craig Reynolds in 1986, and now you will likely find lots of implementations as it’s a nice hobby project (I’ve written it myself a couple of times). Despite its simplicity the model demonstrates rich emergent behaviour and produces flock formations reminiscent of flocks and shoals seen in the natural world.
The model is formed from a set agents referred to as “boids” each moving about the simulated space with the ability to rotate their trajectory (steer). Each boid follows 3 basic rules referred to as separation, alignment and cohesion
- Separation: The boid steers away from any crowding flockmates to avoid collisions
- Alignment: The boid steers toward the average heading of local flockmates
- Cohesion: The boid steers towards the centre of mass of local flockmates
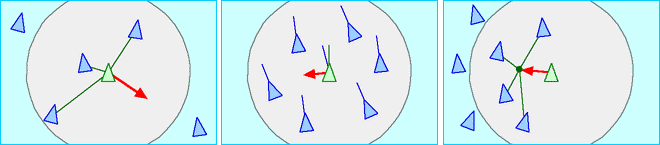
The model progresses stepwise, at each step the boids steering according to the above rules, then updating boid positions in parallel. These generally form the basic flocking rules, though additional rules can be added for more complex behaviour such as avoiding environmental obstacles or seeking goals.
Motivation
In this specific case having coded up boids before, the rules can be hard to optimize, especially as more complex situations are added (for example environmental objects) and different contributions to the steering vector need to be weighed. So it is interesting to investigate if ML can generate nice optimizations of the existing rule, or policies in this RL case.
More generally, working with agent based models in many cases requires modelling and optimizing parameters for large numbers of homogenous (or homogenous subsets of) agents which can serve as a background for more complex parts of the simulation. For example
- An agent based stock market model might contain a large numbers of simple strategy traders that form the background noise of the market
- A traffic simulator may contain large numbers of simple background agents filling out traffic
As model complexity increases it becomes increasingly hard to both manually program robust complex behaviours and optimize parameters that control those behaviours. In this case RL could be a powerful tool to generate complex policies for these agents from simpler goals.
Large scale multi-agent RL comes at the obvious computational cost of running and training large numbers of agents. As such I thought it would be interesting to investigate whether a single RL agent could be used to design a policy for a set of interacting homogenous agents, and can it learn emergent or cooperative behaviours?
Implementation
Training Environment
The environment consists of a flock of agents (boids), their phase space stored as positions $x_{i}$, heading $\theta_{i}$ and speed $s_{i}$ indexed by agent $i$. The agents live on a torus (this avoids the need to track information on the boundaries) such that $x_{i}=0=l$ where $l$ is the width/height of the space (usually normalized to $1.0$).
The action space of the agents are discrete rotations, for example we might use
the values [-π/10, 0, π/10].
The environment treats each agent individually, as such the bulk of the computational work of the environment is generating local views of the flock for each agent, done by shifting and rotating the co-ordinates to centre on each agent, and also relative headings between agents (with the added complication of working on the toroidal space)
- Generate the component matrices $x_{ij} = x_{i} \rightarrow x_{j}$ where $i\neq j$. These are the shortest vectors from agent $i$ to agent $j$ on the torus
- From the components generate the distance matrix $d_{ij}$ the (shortest) Euclidean distance between agents $i$ and $j$
- Generate $\theta_{ij}$ the smallest angle between the headings of pairs of agents
- Sort each agents neighbours by distance from that agent, then only include observations from the nearest $n$ neighbouring agents
- Rotate the shifted vectors to align the axes with each boids heading
- Return the concatenated relative vectors and headings of $n$ nearest neighbours to each agent returning the $n_{\text{agents}}\times 3n$ matrix of observations for each agent
The sorting step ensures that each agents local view should have common features with other agents (as opposed to features arranged according to agent indices).
The rewards signal is based purely on the distances between neighbouring agents $r_{i} = \sum_{j}f(d_{ij})$. Choosing $f(d_{ij})$ was one of the more challenging aspects, an initial choice was as simple binary $f(d_{ij})=1$ if $d_{ij}$ is less than some threshold and $0$ otherwise but this seems not encourage the boids to move closer to each other. A continuous function $\exp(-\alpha d)$ encourages agents to move closer, but due to the toroidal space, and the nature of the flock it seems there are good solutions where a boid is evenly distanced rather than close to other boids.
Along with a penalty for being to close to other boids, the environment currently uses
\[f(d)= \begin{cases} -p & \text{if } d<d_{\text{close}}\\ \exp(-\alpha d) & \text{if } d_{\text{close}}<d<d_{\text{cutoff}}\\ 0 & \text{otherwise} \end{cases}\]where $p$ is a large penalty value, and $\alpha$ controls how the rewards scale with distance.
The step(actions) function of the environment, as per the Open-AI API
accepts actions and advances the model one step. The environment
expects actions for each agent’s, in this case for discrete actions, this would
be a 1d array length $n_agents$ indexing the possible rotations. The step
function in turn returns local observations and rewards for each boid i.e. the
$n_{\text{agents}}\times 3n$ local observation matrix and $n_{\text{agent}}$
rewards.
Agent Based Buffer
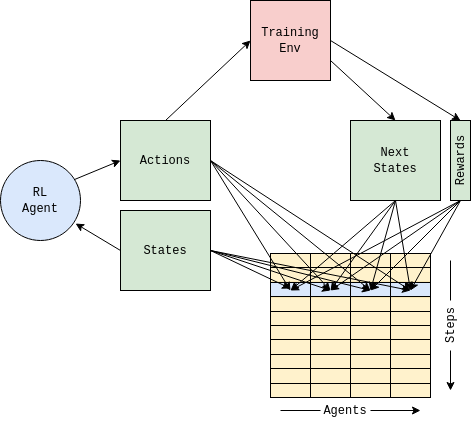
To facilitate the multiple boids of the training environment, I’ve expanded the experience buffer to store the transition values for each agent at every step. The buffer acts as a queue with new values replacing the oldest entries, indexed by the current step and agent index. This is not strictly necessary, a single queue could be used (just pushing the all the agent values in order) but this format should allow for histories to be recalled for each agent as might be required for RL agents using recursive networks.
The training loop then proceeds pretty much as a regular DQN agent with the addition that
- Experience samples are drawn uniformly from the agent and steps
- The actions of the dqn are generated from a matrix of local observations from each agent, generating an array of actions for each agent
Results
Training
Training with this model revealed a number of difficulties:
- Local Minima: The model seemed to have a few local policy solutions the agent can settle on. In particular all agents moving in straight lines or all agents always steering in one direction, both of which clearly produce consistent rewards, and in particularly can produce excellent rewards if agents randomly start close to each other. This seemed to be best mitigated by the appropriate choice of rewards function, or potentially penalising simple behaviour patterns.
- Feedback: Since the agent is only interacting with its own actions as training progresses and the exploration parameter decreases the actions produced by the agent can become highly localised on a few actions as agents only gain experience of the limited (and predictable) actions of the flock as a whole. It may be beneficial to either maintain a subset of boids that act in a random manner, or add randomness to the application of the steering vectors.
- Over-training: Linked to the feedback issue, the model quite easily overtrains. The agent seemingly developing flocking behaviours at an optimal number of episodes, before then loosing a lot of reactive policies past that point.
Results are very sensitive to the parameters of the training environment, in particular the choice of velocity, steering angles and reward function. Despite this some nice results can be produced, demonstrating flocking similar to that produced by the designed boids rules despite the simple reward function. Some nice example are shown below, for increasing number of episodes also showing the results of overtraining.




Further Work
I’ve labelled this post part 1 as I’ve I feel there are a number of interesting directions to take this that I want to follow up on:
- Continuous action space: A discrete action space was chose in this case to make use of a DQN agent, but the extension to a continuous space is simple to implement; allowing for continuous steering values, and potentially changes in velocity.
- Environmental Obstacles: Basic obstacles should be a simple extension, in particular spherical objects, with an associated penalty for interception, should be simple to add.
- Competitive Agents: It may be interesting to add adversarial agents into the model perhaps representing predators, or competition for resources. This agents or agent(s) could then also be driven by an RL agent in the same manner. This may also have the benefit of driving the flock agent to generate more novel and robust policies compared to the simple flocking policy.
- Vision Model: Part of the difficulty in designing the environment was creating observations of the flock with fixed dimensions to be passed to the RL agent. This may actually be easier if this is done using a view model for each agent, i.e. each boids generates pixels representing the field of vision of each boid. This would create a standard observation format that would more easily accommodate additional complexity in the model. In practice though this would likely require a ray tracing for each boid which could be potentially very expensive for large flocks of agents.
Modules for the environment and buffer, as well as examples of usage can be found on the github repo. The environment follows the Open AI gym API so should be compatible with RL agents using this that format!